音声合成ソフトOpen JTalk
下記のURLを参考にインストールしてRaspberry pi zero 2Wで動かしてみました。
ラズパイでも動く音声合成ソフト3選(Open JTalk、VOICEVOX、VOICEPEAK) | ラズパイダ (raspida.com)
まず、aptコマンドで下記のように入力してインストールします。
sudo apt install open-jtalk open-jtalk-mecab-naist-jdic hts-voice-nitech-jp-atr503-m001
インストールが完了したら、しゃべらしてみましょう。
まず、コマンドを実行するシェルスクリプトでを作成しておきましょう。
テキストエディッタのnanoでjvoice-m.shというファイルを作成します。
nano jvoice-m.sh
起動したら下記を張り付けて、ctrl-oで上書きしてctrl-xで終了してください。
#!/bin/sh
TMP=/tmp/jsay.wav
echo "$1" | open_jtalk \
-m /usr/share/hts-voice/nitech-jp-atr503-m001/nitech_jp_atr503_m001.htsvoice \
-x /var/lib/mecab/dic/open-jtalk/naist-jdic \
-ow $TMP && \
aplay -q $TMP
rm -f $TMP
このファイルを実行するには下記のように実行できるようにchmodコマンドで設定しておく必要があります。
chmod +x jvoice-m.sh
使う時は、shファイルがあるフォルダから
./jvoice-m.sh おはよう
と入力します。
「おはよう」としゃべりました。
女性の声も追加しておきます。
wget http://downloads.sourceforge.net/project/mmdagent/MMDAgent_Example/MMDAgent_Example-1.8/MMDAgent_Example-1.8.zip
unzipコマンドで解凍します。
unzip MMDAgent_Example-1.8.zip
次に解凍した内容を/usr/share/hts-voice/へコピーします。
sudo cp -R ./MMDAgent_Example-1.8/Voice/mei /usr/share/hts-voice/
先程の男性音声とコードは同じでも、-mの引数であるパスは変更します。(4行目)
先ほど作成したシェルスクリプトjvoice-m.shの時と同じように女性用のファイルを作成します。
nano jvoice-w.sh
中身は下記です。
4行目の-mの引数で、先ほどダウンロードして解凍コピーした女性用のデータを示します。
#!/bin/sh
TMP=/tmp/jsay.wav
echo "$1" | open_jtalk \
-m /usr/share/hts-voice/mei/mei_normal.htsvoice \
-x /var/lib/mecab/dic/open-jtalk/naist-jdic \
-ow $TMP && \
aplay -q $TMP
rm -f $TM
このファイルを実行するには下記のように実行できるようにchmodコマンドで設定しておく必要があります。
chmod +x jvoice-w.sh
./jvoice-w.sh こんにちは
女性の声で「こんにちは」としゃべりました。
お天気時計を作ろうとしているので時報やお天気を知らせるのにこの音声合成は使えそうです。
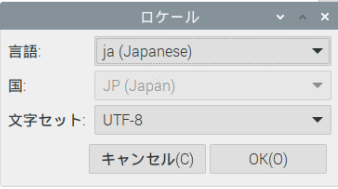
注意)文字の認識がおかしかったので、文字セットを変更しました。
「設定」→「Raspberry piの設定」の「ローカライゼーション」のタブを開いて
pythonのコードでファイルを読み込んでしゃべらすこともできます。
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
import subprocess
# textfile
TEXT_FILE = "jvoice-text.txt"
# openjtalk
X_DIC = '/var/lib/mecab/dic/open-jtalk/naist-jdic'
#M_VOICE = '/usr/share/hts-voice/nitech-jp-atr503-m001/nitech_jp_atr503_m001.htsvoice'
M_VOICE = '/usr/share/hts-voice/mei/mei_normal.htsvoice'
# M_VOICE = '/usr/share/hts-voice/mei/mei_normal.htsvoice'
R_SPEED = '1.0'
OW_WAVFILE = '/tmp/tmp.wav'
# aplay
# CARD_NO = 1
# DEVICE_NO = 0
def talk_text(t):
open_jtalk = ['open_jtalk']
xdic = ['-x', X_DIC]
mvoice = ['-m', M_VOICE]
rspeed = ['-r', R_SPEED]
owoutwav = ['-ow',OW_WAVFILE]
cmd = open_jtalk + xdic + mvoice + rspeed + owoutwav
c = subprocess.Popen(cmd, stdin=subprocess.PIPE)
c.stdin.write(t.encode('utf-8'))
c.stdin.close()
c.wait()
# aplay = ['aplay', '-q', OW_WAVFILE, ('-Dplughw:'+str(CARD_NO)+','+str(DEVICE_NO))]
aplay = ['aplay', '-q', OW_WAVFILE]
wr = subprocess.Popen(aplay)
wr.wait()
def main():
with open(TEXT_FILE) as f:
for line in f:
talk_text(line)
if __name__ == '__main__':
main()
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー